本文最后更新于:2025年5月7日 上午
背景 Adv-Makeup是由腾讯优图实验室提出的一种可以在物理世界进行黑盒攻击人脸识别模型的一种方法。
Deep neural networks, particularly face recognition models, have been shown to be vulnerable to both digital and physical adversarial examples. However, existing adversarial examples against face recognition systems either lack transferability to black-box models, or fail to be implemented in practice. In this paper, we propose a unified adversarial face generation method - Adv-Makeup, which can realize imperceptible and transferable attack under the black-box setting. Adv-Makeup develops a task-driven makeup generation method with the blending module to synthesize imperceptible eye shadow over the orbital region on faces. And to achieve transferability, Adv-Makeup implements a fine-grained meta-learning based adversarial attack strategy to learn more vulnerable or sensitive features from various models. Compared to existing techniques, sufficient visualization results demonstrate that Adv-Makeup is capable to generate much more imperceptible attacks under both digital and physical scenarios. Meanwhile, extensive quantitative experiments show that Adv-Makeup can significantly improve the attack success rate under black-box setting, even attacking commercial systems. In addition, our paper is accepted by the IJCAI 2021, the top artificial intelligence conference all over the world.
但原文所开源的代码仅实现了给定数据集范围内的人脸眼妆叠加实现,且没有预留接口。
代码实现思路 总体架构 核心组件 :
生成器(Generator) :由编码器(Encoder)和解码器(Decoder)组成,用于生成对抗性化妆图像。判别器(Discriminator) :用于区分生成的化妆图像与真实的化妆图像,帮助生成器提高生成图像的真实性。面部识别模型(FR Models) :多个预训练的FR模型(如IR152、irse50、facenet等)用于评估生成的对抗性化妆是否有效。
工作流程
数据准备 :
加载未化妆和真实化妆的眼部图像及其面部关键点。
对图像进行裁剪、归一化和转换,形成训练样本。
模型初始化 :
初始化生成器(Encoder & Decoder)和判别器(Discriminator)。
加载多个预训练的FR模型,用于计算目标损失。
训练过程 :
判别器训练 :通过区分真实化妆图像和生成化妆图像,提升判别器的辨别能力。生成器训练 :通过最小化对抗性损失、目标损失(欺骗FR模型)、风格损失(保持化妆风格)、梯度损失(保持图像边缘)和总变差损失(减少图像噪声),优化生成器生成有效的对抗性化妆图像。
模型保存与可视化 :
定期保存模型参数,记录训练日志。
保存生成的化妆图像和中间结果,便于监控训练进展和效果。
代码解析 train.py实现了模型训练,它训练的目标是得到一个GAN生成对抗网络。其中包含一个生成器和一个判别器。
生成器:
编码器:负责提取输入未化妆眼部图像的特征表示。
解码器:根据编码器提取的特征生成具有对抗性的化妆图像。
判别器:
负责区分生成的对抗性化妆图像与真实的化妆图像,从而提升生成图像的真实性和欺骗性。
最终通过train.py训练出一个能够生成具有自然外观且能欺骗多种面部识别模型的对抗性化妆图像的模型。
dataset.py用于处理数据集,对图像进行裁剪和处理。
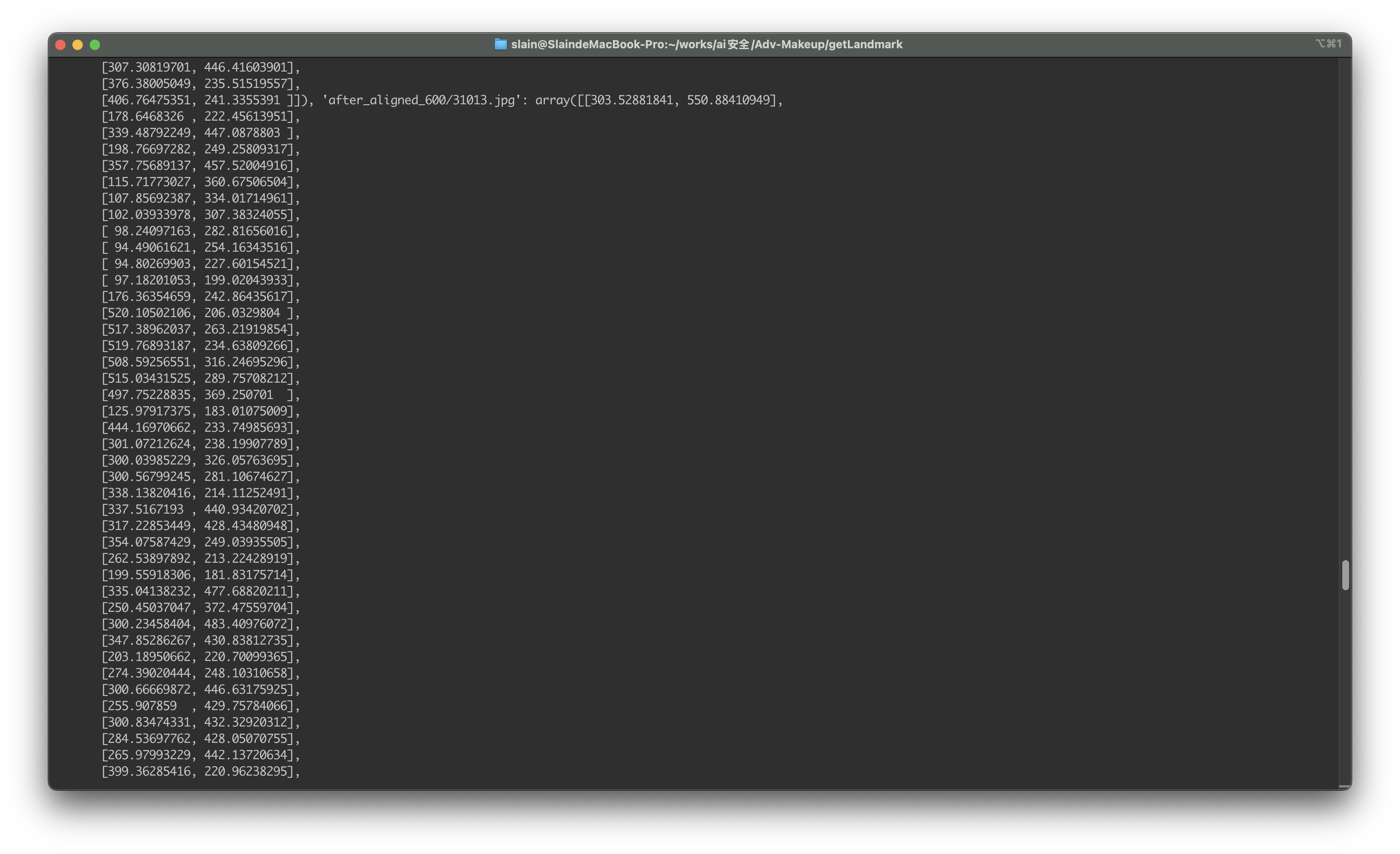
源代码中在数据集目录下保存了一个pickle序列化文件,我们使用如下代码解析其
1 2 3 4 5 6 7 import pickle
结果如下
可以看到其中保存着106个点的landmark数组。通过解析这些landmark数组获取眼部区域,利用前面训练的模型进行眼影叠加。
Patch源仓库 支持mps的cpu训练 对model.py进行patch:
1 self.device = torch.device('mps:{}'.format(config.gpu)) if config.gpu >= 0 else torch.device('cpu')
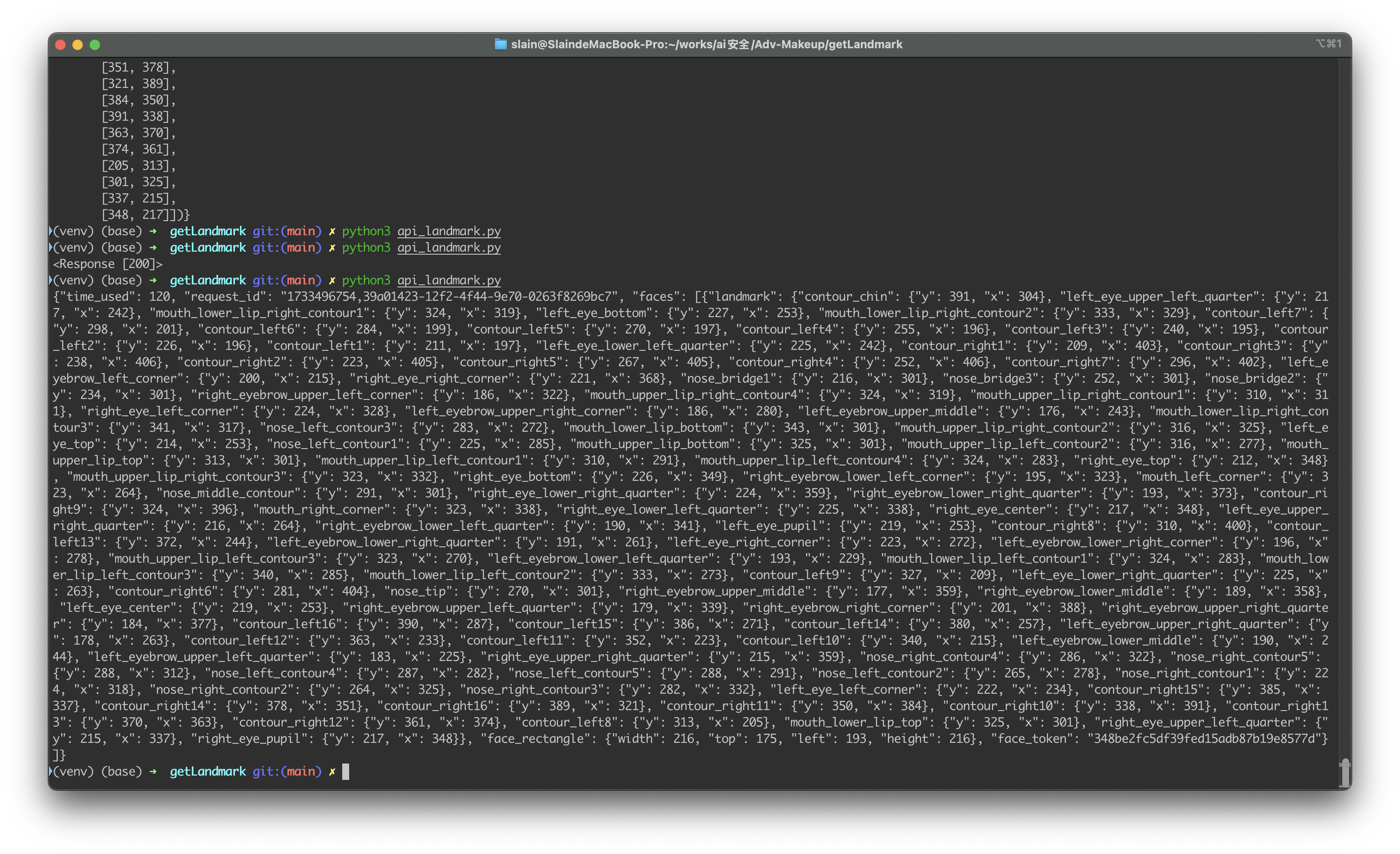
获取任意人脸的106点的landmark并合并入原数据集 在尝试了dlib,mediapipe后发现均无106点的landmark标注方式。我们尝试使用网络api对图像进行标注。
使用Face++ API来处理图像的landmark
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 import requestsimport cv2import numpy as npimport pickleopen ("../Datasets_Makeup/landmark_aligned_600.pk" ,"rb+" )'***' '***' 'image/0.jpg' with open (image_path, 'rb' ) as image_file:'https://api-cn.faceplusplus.com/facepp/v3/detect' 'https://api-cn.faceplusplus.com/facepp/v3/face/analyze' 'api_key' : API_KEY,'api_secret' : API_SECRET,'image_file' : image_data,'return_landmark' : 0 ,'return_attributes' : 'none' 'image_file' : image_data}, data=detect_params)if detect_response.status_code == 200 :'faces' , [])if not faces:print ("未检测到人脸。" )else :'face_token' ] for face in faces]'api_key' : API_KEY,'api_secret' : API_SECRET,'face_tokens' : ',' .join(face_tokens),'return_landmark' : 2 ,'return_attributes' : 'none' if analyze_response.status_code == 200 :'faces' , [])for face in faces_analyze:'landmark' , {})for point in landmarks.values():'x' )'y' )"before_aligned_600/0.jpg" ] = np.array(landmark_coords)print (landmarks_dict)open ("../Datasets_Makeup/landmark_aligned_600_new.pk" ,"rb+" )else :print (f"人脸分析请求失败,状态码: {analyze_response.status_code} " )print (f"错误信息: {analyze_response.text} " )else :print (f"人脸检测请求失败,状态码: {detect_response.status_code} " )print (f"错误信息: {detect_response.text} " )
调用api得到landmark
合并生成一个新的pk序列化文件供重新训练。
剪裁需要新加入的图像文件 在我们的dataset.py中对图像进行张量化的时候写死了图像的尺寸数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import torch.nn.functional as Fdef paste_patch (self, fake_after, before_path, target_name ):600 , 600 )for img in fake_after:if (h, w) != target_size:0 ), size=target_size, mode='bilinear' , align_corners=False ).squeeze(0 )for idx, tensor in enumerate (before_pasted):print (f"After resize - Tensor {idx} size: {tensor.size()} " )0 ) return before_pasted
我们需要实现自动化的剪裁图片的尺寸为600x600。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from torchvision import transforms600 , 600 )),def load_image (image_path ):open (image_path).convert('RGB' )return image
重新进行训练
训练后使用test.py生成新的攻击图像
至此实现了对源仓库的patch,实现了对任意图像的眼影叠加。
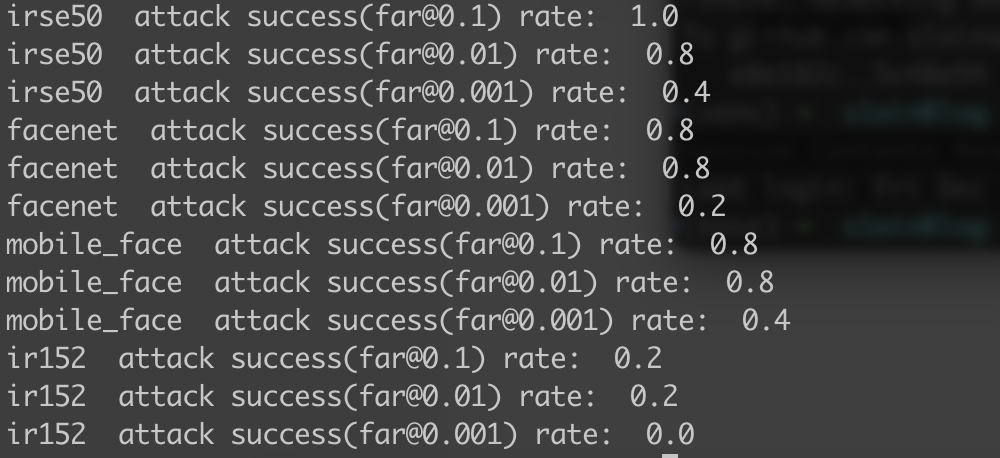
最终效果
攻击成功